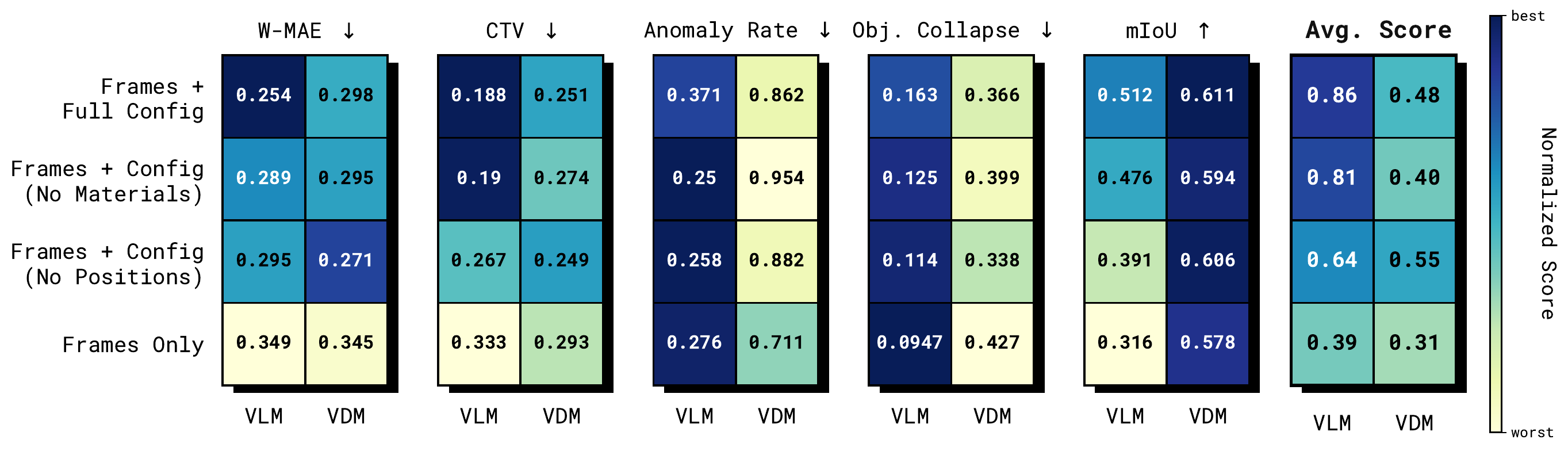
Quantitative Results
Aggregate metrics from the held-out test split. Below we summarize how code generation and video diffusion compare across input conditions, materials, and prediction horizon — complementing the qualitative examples above.
Overall comparison
Normalized scores across evaluation metrics and input regimes. Lower is better for W-MAE, CTV, anomaly rate, and object collapse; higher is better for mIoU. The rightmost column averages across metrics. Code generation is stronger on temporal stability and long-horizon consistency; video diffusion leads on spatial overlap (mIoU).
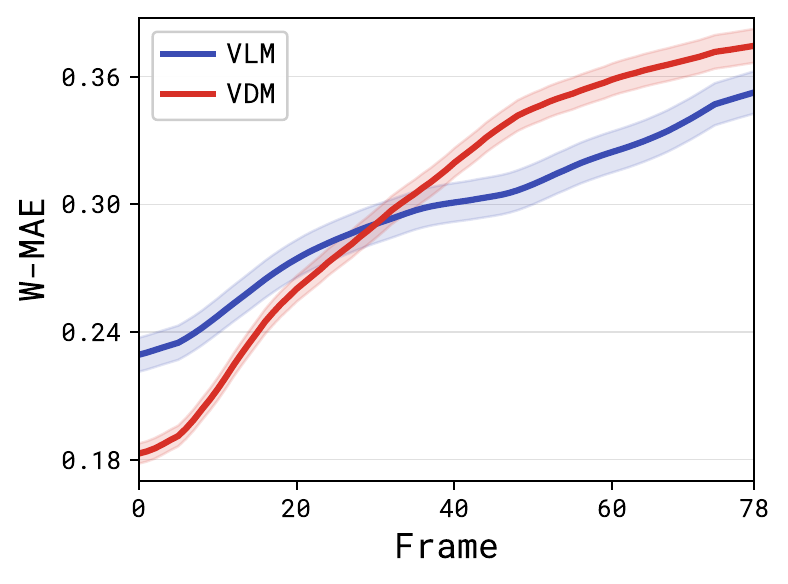
Error grows with horizon
Moving-average W-MAE over continuation frames. Video diffusion motion error grows faster with prediction horizon than code generation, reflecting accumulated temporal drift in pixel-space extrapolation.
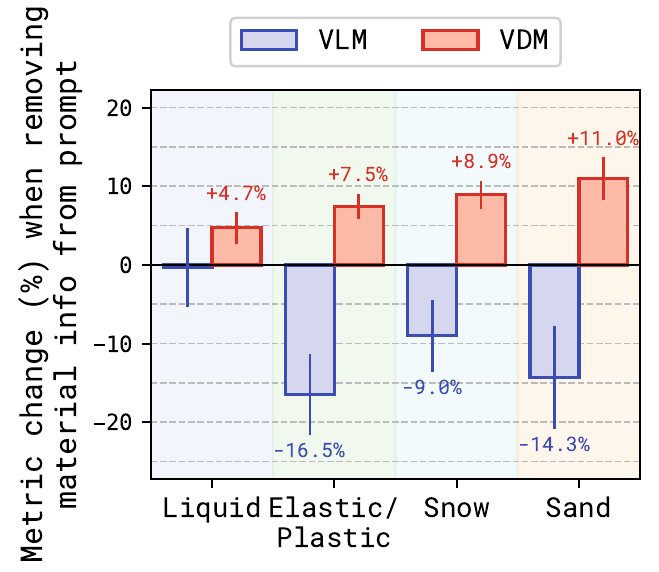
Sensitivity to material info
Performance change when material information is removed from the prompt, by material family. VLMs degrade on elastic, snow, and sand scenes; liquids are less affected. VDMs change little — they rely mainly on pixels, not structured material specs.
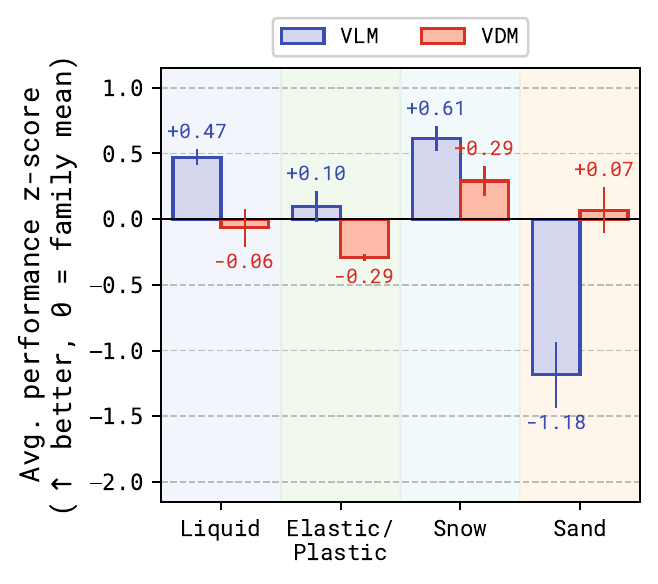
Performance by material
Average normalized score by material family (zero = model-family mean). Code generation is strongest on liquids and snow, weakest on sand. Video diffusion struggles most on elastic/plastic scenes where coherent trajectories must persist over time.